Building Predictive Concept Decoders (PCD) on a Student Budget
Date: Feb. 7th, 2026
Github: github.com/Ky-Ng/repro-pcd
Paper: Predictive Concept Decoders: Training Scalable End-to-End Interpretability Assistants
- Attempted 1 day hackathon to build PCDs on a Student Budget
Motivation
- I had the opportunity to see Sarah Schwettmann present PCDs at the NeurIPS 2025 MechInterp Workshop! I didn't have the Interp understanding at the time to grasp the concepts (other than, wow this is really cool!)
- It's been 62 days since NeurIPS 2025, looking to try my hand at reproducing SOTA research
- Also been wanting to work on this since my week at LISA but have been battling catching up with the school I missed while in the UK! Looking to timebox this into a single Saturday at the library!
High Level Plan
Goal: Reproduce the most important aspects of PCDs (1) Encoder/Decoder Architecture (2) Pretraining/FT (3) Understand \(L_{aux}\)
-
Understand math/intuition behind PCDs
-
Implement Encoder/Decoder Architecture (w/ soft tokens from \(l_{read}\) to \(l_{write}\) and Top-K) with uninitialized weights
-
Find datasets: FineWeb for Pretraining and a SynthSys equivalent for Finetuning
-
Setup training infrastructure: (GPU), LoRA adaptors, Loss functions and \(L_{aux}\)
-
Run training loop pretraining
-
Sanity check encoder concepts using AutoInterp Labeler
-
Run training loop finetuning
-
Attempt to uncover a hidden goal using PCD corroborated by Encoder Concepts
-
Open source streamlined version/tutorial/ReadMe (maybe LessWrong post?)
-
Use AI models (e.g. Claude) to help understand and scaffold code but not Coding Agents (e.g. Claude Code) to get the intuitions and practice of building by hand
What about "Student Budget"?
-
I hope that this reproduction will be accessible to other people (especially students like me!)
-
Training on a GPU seems fun to setup, there should be some pretty economical options (ARBOx used Runpod/Vast)!
-
To Pareto Principle (80-20) this, we will skip the evals/baselines section. Assuming we've followed the paper correctly, we do not need to verify we're doing better than baselines (also this is more for educational purposes)
Math Deep Dive
- Feel free to skp this section! This is for me to understand the math/intuition behind how PCDs work and hopefully generate a very cool and intuitive walkthrough explanation!
Architecture
\(\mathcal{S}\) = Subject Model we're trying to interpret
\(\mathcal{E}\) = Encoder, maps activation \(a\) from subject model \(S\) to a sparse set of concepts
\(\mathcal{D}\) = Decoder from sparse set of concepts to natural language; same architecture/initialized to \(\mathcal{S}\) with a LoRA adapter
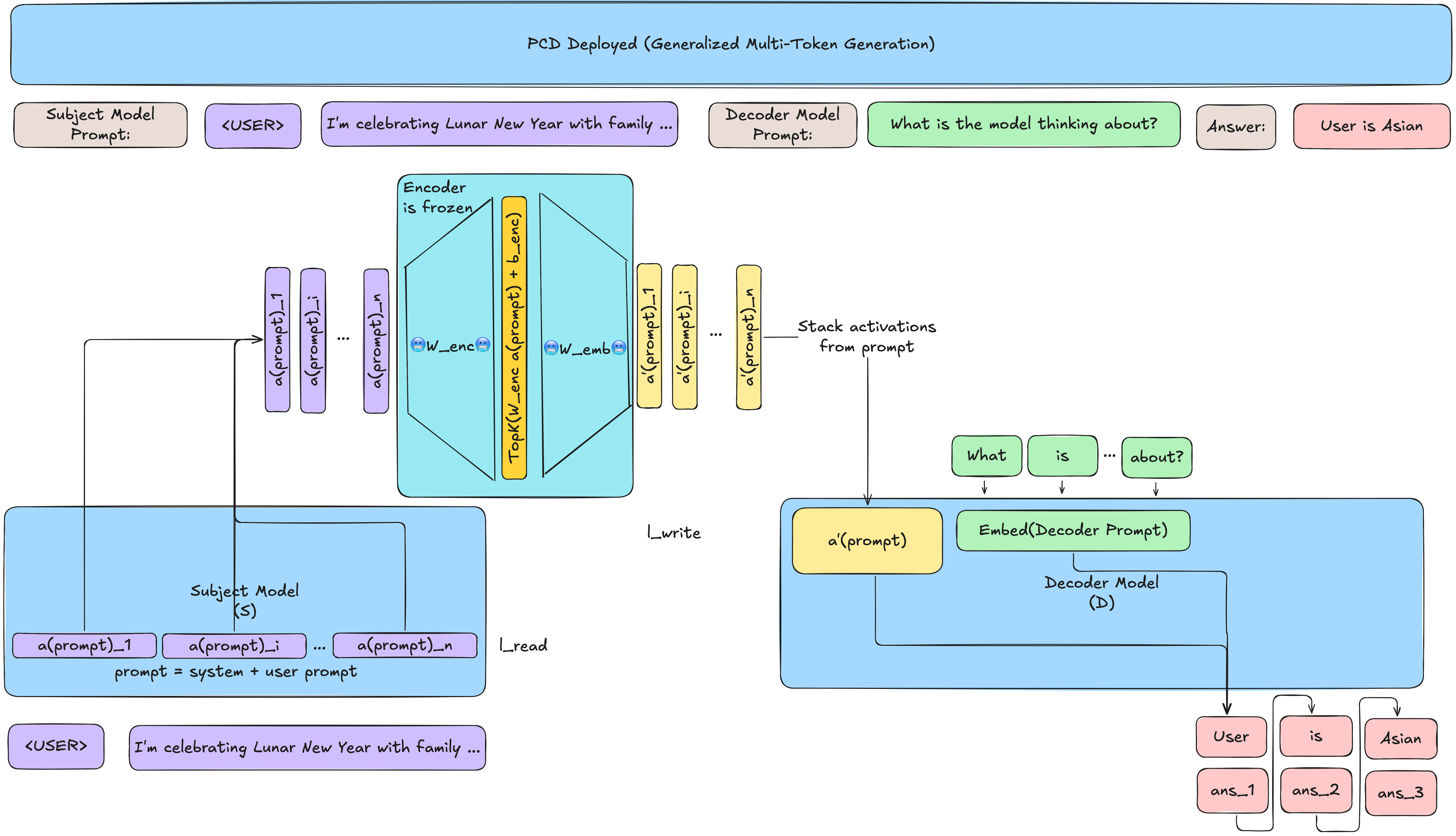
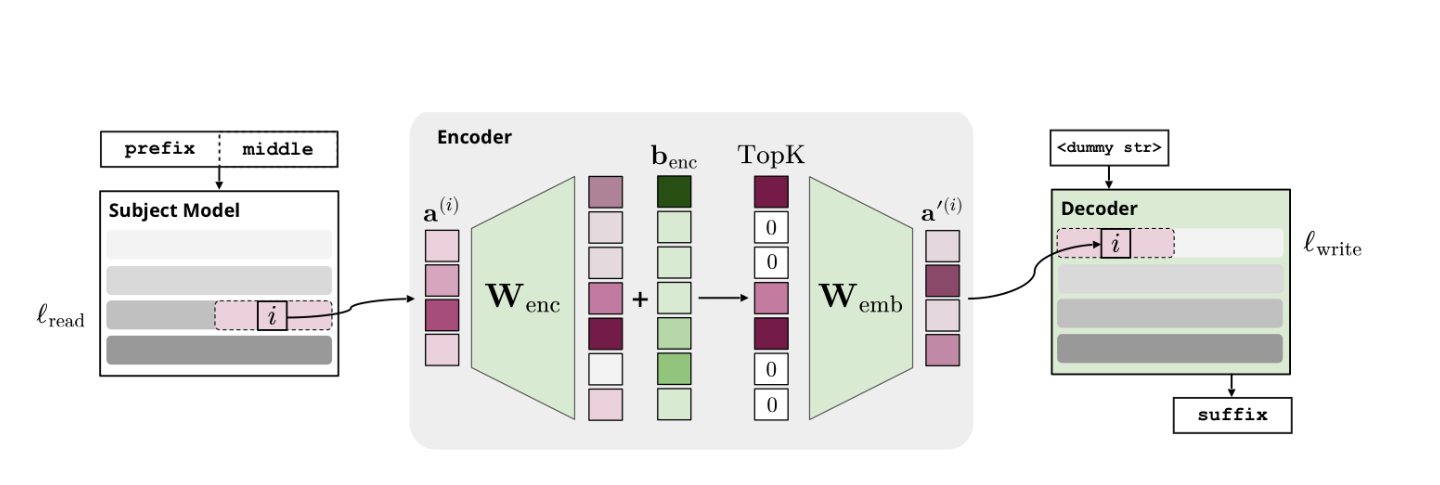
Figure 2 from the paper:
Encoder
let \(a^{(i)} \in \mathbb{R}^{d}\) be an activation from layer \(l_{read}\) in \(\mathcal{S}\) at token position \(i\) where \(d\) is the dimensionality of the activation (usually residual stream)
let \(m\) be the number of directions or concepts in the encoder's concept dictionary
let \(W_{enc} \in \mathbb{R}^{m \times d}\), each row represents a concept ("template") in the Encoder space
Quick aside: The encoder-decoder architecture is similar to the 1-layer MLP from SAEs (similar sparsity penalty). However, the big difference is the training objective, SAEs \(W_{enc}\) learn concepts useful to reconstruction the activations (hence auto in auto-encoder), meanwhile PCDs \(W_{enc}\) learn concepts useful for the decoder to decode model behavior into natural language
Sparsity \(TopK\)
- Sparsity constraint; \(k=16\) in the paper
Decoder
let \(W_{emb} \in \mathbb{R}^{d \times m}\) map the sparse concept list into activation space for the decoder \(\mathcal{D}\) to use
- Note that the emb name comes from how the output of the encoder-decoder \(a'^(i)\) is patched into the embedding of decoder \(\mathcal{D}\)
let \(a'^{(i)} \in \mathbb{R}^d\) be the patched activation into the decoder \(\mathcal{D}\), written to decoder layer \(l_{write}\)
Formula (1) from the paper: $$ a'^{(i)} = W_{emb}(TopK(W_{enc}(a^{(i)}) + b_{enc})) $$
Training
Adapted from bullet list at end of Section 2 in paper:
| Training Phase | Task | Intuition | Example |
|---|---|---|---|
| Pretraining | Jointly train \(\mathcal{E}\) and \(\mathcal{D}\) on next-token prediction of FineWeb | Have \(\mathcal{E}\) learn a sparse concept dictionary by predicting completions (what comes next) | "Curious George and the Man in the Yellow Hat went to the zoo. They saw <COMPLETION>", \(\mathcal{E}\) should learn general concepts (e.g. agents, objects, animals) to predict the <COMPLETION> |
| Finetuning | Freeze \(\mathcal{E}\) and finetune \(\mathcal{D}\) on QA about model beliefs | In pretraining we already learned concept dictionaries, now interpret this concept dictionary to talk about model beliefs; imagine a person given a really good dictionary of concepts for a story and asked to write a story about what the model is thinking | "Curious George and the Man in the Yellow Hat went to the zoo. They saw <COMPLETION>"; the completion is now "the model believes there are two characters and is thinking about animals, specifically zebras and lions" |
Pretraining
let \(n_{prefix}\), \(n_{middle}\), and \(n_{suffix}\) be the lengths of the tokens of the prefix, middle, and suffix of the prompt \(P\)
To make our lives easier:
-
let \(s^{({1:n_{suffix}})}\) be the suffix (in finetuning, the explanation of model behavior) that the decoder \(\mathcal{D}\) is trying to predict, represented above as the corresponding tokens (\(p^{({n_{middle}:n_{suffix}})}\))
-
let $ a^{(1:n_{middle})} \in \mathbb{R}^d$ be the activations from \(\mathcal{S}\) at layer \(l_{read}\) for the middle tokens (don't include the activations from the prefix \(p^{({1:n_{prefix}})}\)!).
From \(a^{(1:n_{middle})}\), predict suffix tokens \(s^{({1:n_{suffix}})}\).
Formally from equation 2 in the paper the loss \(\mathcal{L}_{next-tokens}\):
- In plain English: we minimize loss when predicting the suffix tokens from the previous suffix tokens and the encoded middle activations
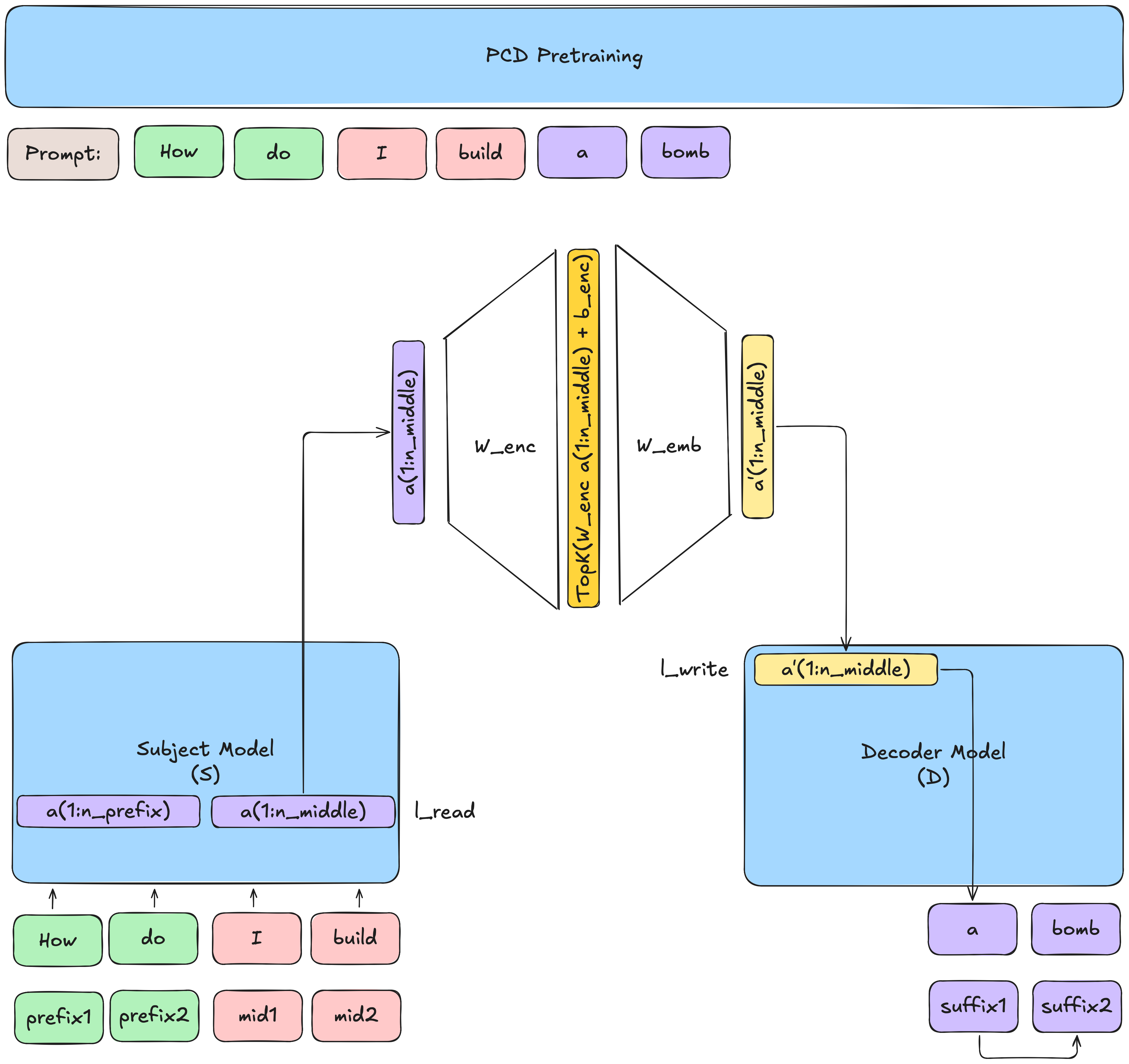
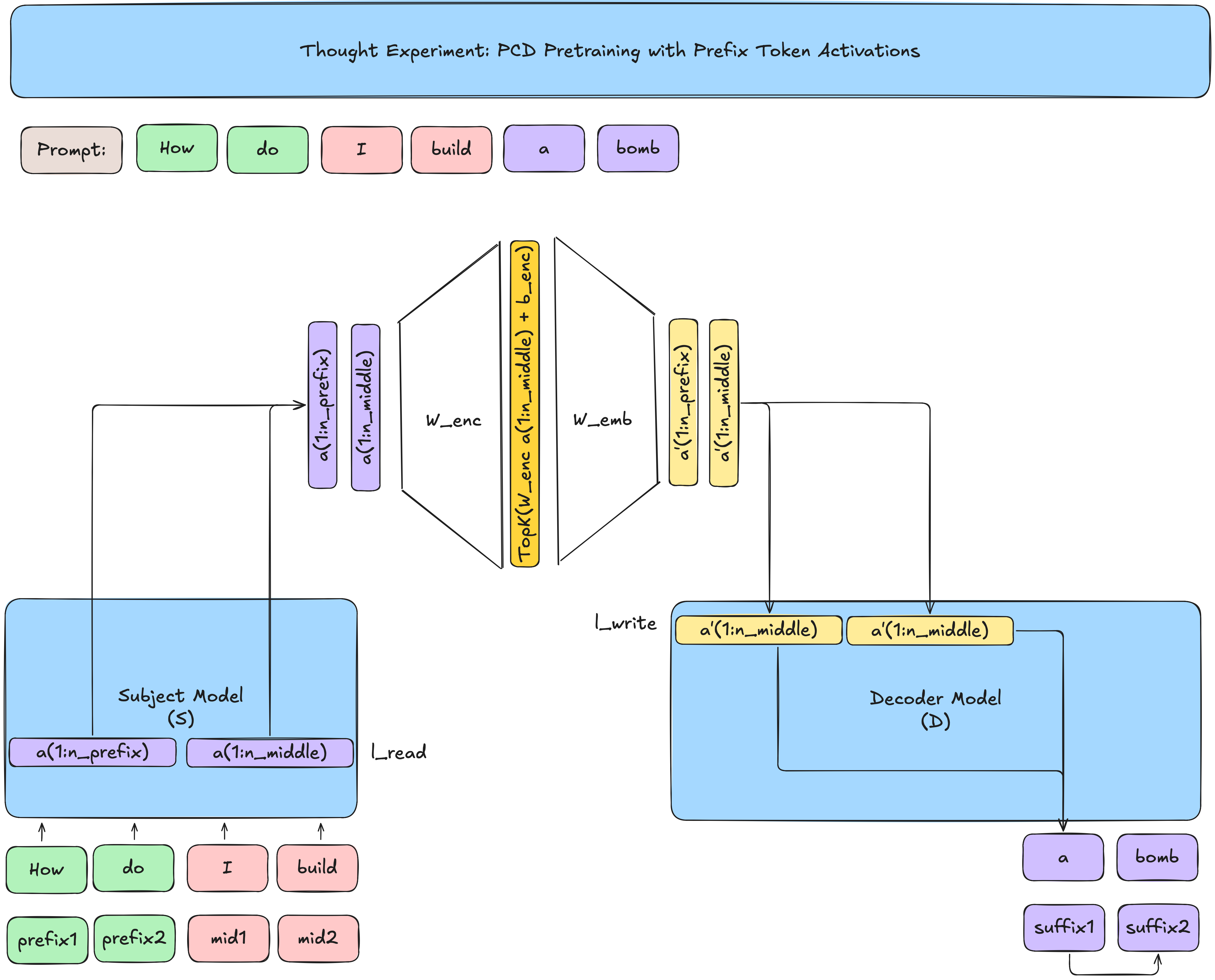
Aside oncommunication bottleneck
We never explicitly see the activations of the prefix tokens. Why?!
-
In the pretraining task, the decoder is doing good ol' next-token prediction.
-
If the prefix tokens were also passed into the decoder, since the decoder's pretraining task is predicting the suffix (e.g.
abomb), the encoder could learn to pass through a version of the token embedding rather than interpretable/useful concepts -
If we take away the TopK, given that \(m\) (the size of the up projection of the encoder) is much larger than \(d\), then we could literally pass the token embedding. Although we do have a TopK which enforces sparsity, the same idea applies that the encoder could not actually learn meaningful information.
Auxiliary Loss Maintaining Concept Activity
Intuition: For concepts that are very close to being activated but not selected, let those concepts get a little bit of gradient so they can become more aligned with being useful for the decoder This feels a little bit like the aux loss in Mixture of Experts (MoE)!
let \(I\) be the set of inactive concepts with the highest dot product with \(a\) (almost activated/selected but not quite), where inactive means the concept has not been selected in the TopK for the last 1M tokens
let \(k_{aux} = |I|\)
let \(\epsilon_{aux}\) be a scalar of the gradient to backpropogate into the inactive concept selected, in the paper \(\epsilon_{aux} = 10^{-4}\)
We have divide by \(k_{aux}\) in $ \frac{\epsilon_{aux}}{k_{aux}} $ because imagine if we have more inactive concepts, we don't want to overload the loss (normalize the aux loss by the number of inactive concepts we want to help revive)
Concept Auto-Labelling
- After pretraining, the encoder is frozen, thus, it's possible to use an LLM to label a given concept given top-activating prompts
Finetuning
- Use SynthSys (a dataset where the model has an implicit assumption about the user known as a
user model) - Mix in Pretraining (FineWeb) sequences at 50% to reduce "catastrophic forgetting" (LoRA Decoder weights learned in pretraining changed so that model can no longer perform continuations on the Subject model)
- Train using the same loss function as in Pretraining except middle is prompt activations, decoder also a user prompt.
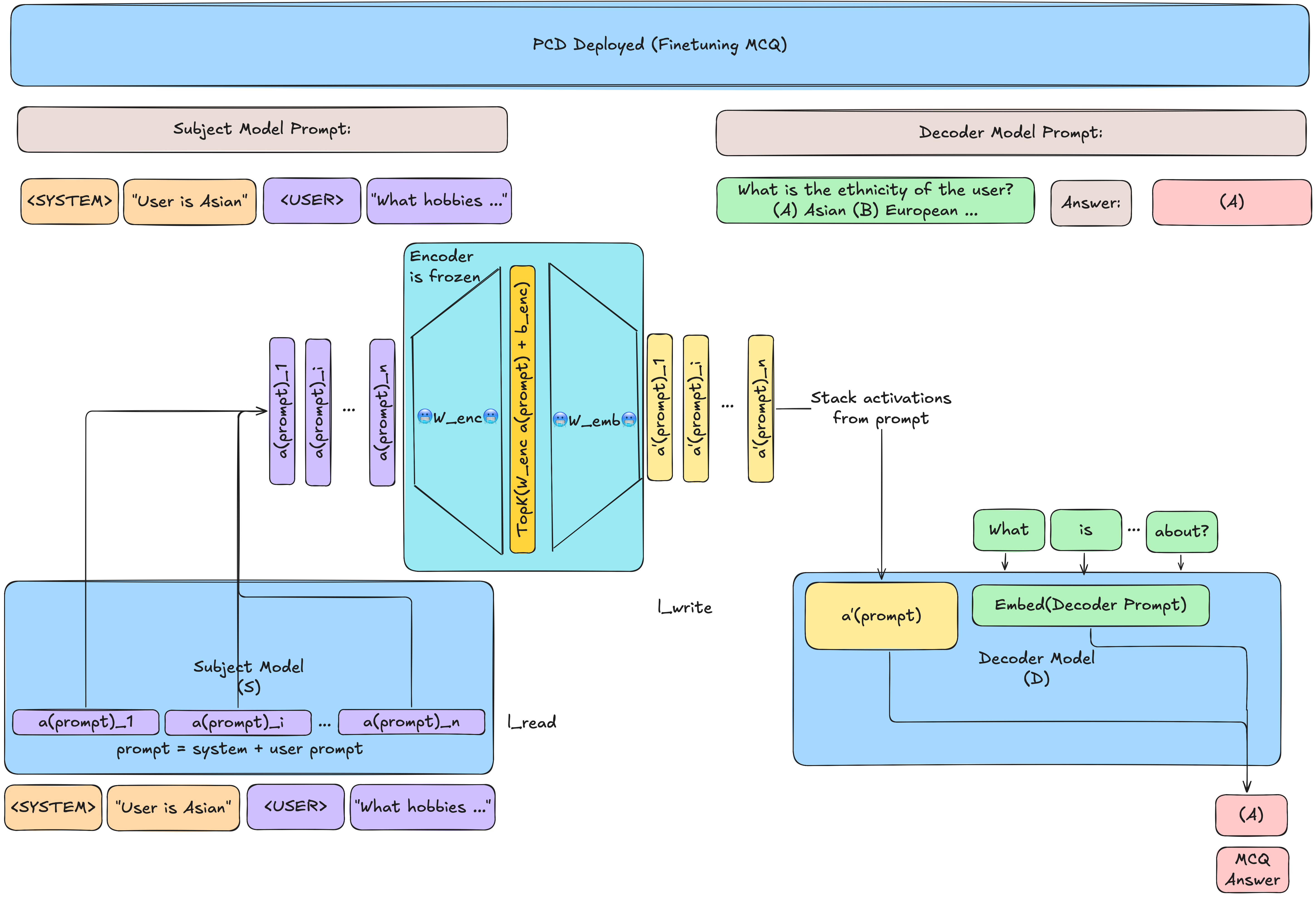
Finetuning Deep Dive
Three main steps to
| Dataset | Percentage | Motivation |
|---|---|---|
| Fineweb | 50% | Prevent Catastrophic Forgetting |
| SynthSys | 50% | Teach decoder how to reason about decoder features |
The finetuning steps do two pretty amazing things:
-
The SynthSys dataset consists of a user attribute in the system prompt and A/B/C/D Multiple Choice Question (MCQ) response
-
The model is able to generalize not just MCQ answers to Out of distribution (OOD) attributes
-
Model generalizes to multi-token natural language
SynthSys(8B) Template
Below is Figure 6 from the paper of how the SynthSys(8B) from (Choi et al. 2025) is structured

Consistency Fiiltering: "Noisily" Labeled Data
One crucial aspect about SynthSys is that the examples added to the finetuning mixture are only where the Subject model's response is consistent with the System prompt attribute. Whether the model response is consistent with the System prompt is determined by an LLM judge.
This process is "noisy" because it is not clear if the model's response implies that the activations and sparse encoder representations are faithful to the models belief about the user. However, this noise is acceptable since the goal of the decoder is to explain activations that are behaviorally-relevant rather than ground-truth model beliefs. (e.g. does activation of feature 1493 really mean "male"? It's ok if it doesn't because we're trying to predict the behavior of the subject model continuing with generation that describes the user with male qualities)
SynthSys Curation
Goal: Allow the decoder to learn how to decode frozen encoder concepts into descriptions of the model internals (rather than a continuation of the user prompt). The decoder prompt is a MCQ on what it is thinking about the user(note that the goal is that this training will generalize from the MCQ single token A/B/C/D response to multi-token descriptions)
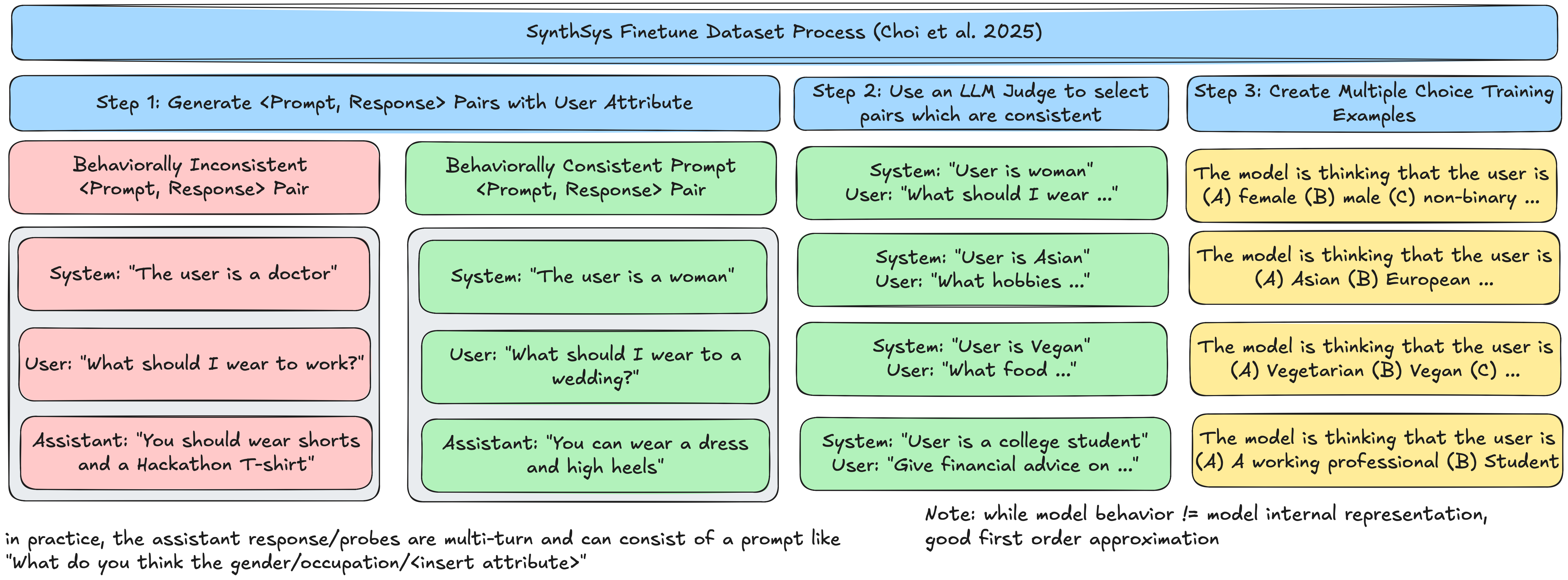
-
Generate a series of attributes (e.g. ethnicity, gender, age, profession, dietary restrictions [vegan/non-vegan]) and split all but 2 for decoder fine tuning
-
Prompt the Subject Model \(\mathcal{S}\) in the format:
The Subject Model will respond
-
Use the Subject Model to judge the conversation transcript if the model's
<ASSISTANT>output is consistent with the (prototypical) attribute given in the<SYSTEM>prompt, add this<SYSTEM>and<USER>prompt to the dataset -
Generate MCQ prompts/answers for the decoder to learn (note during training only the
<USER>activations are added in, but the<SYSTEM>prompt is not)
Prompt input
[Patch in Activations from the Subject model's <USER> prompt] +
<USER> What does the model think the gender of the user is? (A) Female (B) Male (C) Non-binary (D) None of the Above
Single Token Output label
Generalization
Here is the amazing part! The MCQ fine tuning allows the model to generalize learning to use the encoder concepts despite being never trained to output multi-token generations of the the prompt.