2026-04-15 | PCD Finetuning Padding
Goal: PCD Debug Batched Finetuning
Summary: Feedback from PCD author Vincent Huang on a batched training issue
Work sessions
| In | Out |
|---|---|
| 21:30 | 22:00 |
Questions:
-
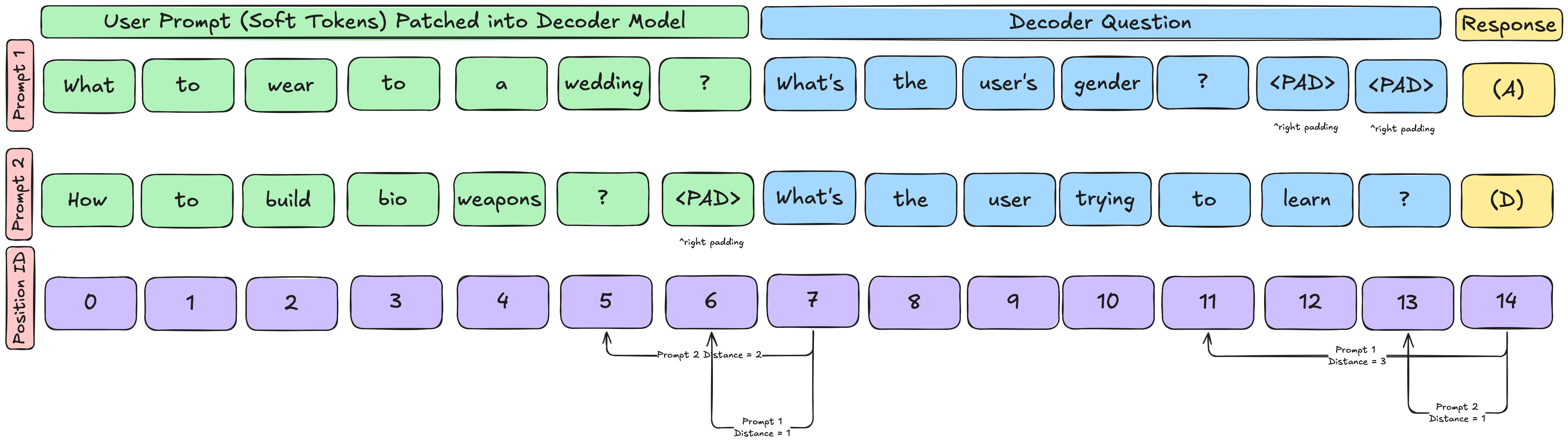
Section 4 Finetuning setup: Are SynthSys dataset "Decoder Question" included as part of the training loss or if the training signal is only a single multiple-choice-question token?
-
Practical challenges on (left/right) padding in batch fine tuning with different lengths of soft tokens:
a. While not a problem in pretraining with fixed (n_prefix, n_middle, n_suffix) lengths, SynthSys finetuning may have different length System messages and Decoder questions.
b. Masking PAD tokens fix tensor batch shape inconsistencies. However, would PAD tokens which still occupy a token index and thus calculate incorrect relative positions with RoPE?
Response from Vincent
- the question tokens never appear in the training loss
- you should take the combined soft token + decoder question sequence (without padding each one individually) and left-pad the combined sequence